The right kind of variance
Tags:
#Event Data
#Prediction
#Variance
#Variance Decomposition
or, How I learned to stop worrying and love event data. (This post first appeared on Predictive Heuristics)
Nobody in their right mind would think that the chances of civil war in Denmark and Mauritania are the same. One is a well-established democracy with a GDP of $38,000 per person and which ranks in the top 10 by Human Development Index (HDI), while the other is a fledgling republic in which the current President gained power through a military coup, with a GDP of $2,000 per person and near the bottom of the HDI rankings. A lot of existing models of civil war do a good job at separating such countries on the basis of structural factors like those in this example: regime type, wealth, ethnic diversity, military spending. Ditto for similar structural models of other expressions of political conflict, like coups and insurgencies. What they fail to do well is to predict the timing of civil wars, insurgencies, etc. in places like Mauritania that we know are at risk because of their structural characteristics. And this gets worse as you leave the conventional country-year paradigm and try to predict over shorter time periods.
The reason for this is obvious when you consider the underlying variance structure. First, to predict something that changes, say dissident-government conflict, the nature of relationships between political parties, or political conflict, you need predictors that change.
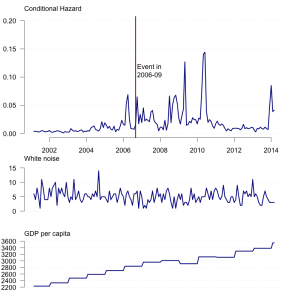
Predictions for regime change in Thailand from a model based on reports of government-dissident interactions (top). White noise, with intrinsically high variance, is not helpful (middle), but neither is GDP per capita (bottom).
This is of course a minimal and necessary condition only. White noise inherently has a lot of variance but it won’t predict regime change in a country well. Even if a variable turns out to be a good predictor, the fact that it is correlated with an outcome of interest might be nice but doesn’t mean that the relationship makes sense. In fact, with enough data, you are bound to find some correlations purely due to chance. So sometimes it’s good to have concepts and some argument relating them to each other and explaining why the correlation is not spurious. But those nice things aside, at the end of the day, there is no statistical model or technique that can get around the fact that the inputs need to have variance.
The reason most existing models do not, and cannot possibly, predict the timing of outcomes of interest well is that they are based on structural variables that change little within any given country over time, even if they change a lot between countries. Take GDP. It has a lot of variance overall, but most of it is between countries: the standard deviation of country averages from the global mean of $10,684 is $15,400, while annual fluctuations are around 2 ± 6% from the previous year (95% margin, using 2011 and 2012 WDI data). Similarly with regime types. Sometimes there are dramatic shifts in countries as a result of revolution or coup, and sometimes there is gradual shift over time as a regime liberalizes or slides to authoritarianism, but mostly it is stable for years at a time.
Partly this is a measurement issue. Many of the standard variables, like GDP, population, and military expenditures, are available in annual formats, which is why the plot of GDP above appears step-like. There already are enough measurement questions with thinks like GDP as it is, and it doesn’t seem likely that we will have quarterly or monthly data with global coverage soon. Other data efforts like the Polity coding of regime types and the COW and UCDP conflict datasets are available in case formats that delineate start and end dates, but which when extrapolated produce series that are a succession of constants with abrupt shifts when going from one state to another state.
On a more basic level though, these structural variables are inherently slow moving. Even if we measured GDP, for example, at a finer temporal resolution it might give us some fluctuations month to month, but the underlying trend is still only going to change gradually over a longer time period. The ultimate example of this is the fraction of a country that is mountainous as a predictor in early civil war models (~2003).
To get models that can predict the timing of political events well, whether at the country-year level or with higher-resolutions, we will have to move away from the set of traditional structural variables, and towards indicators that are more volatile over time. Like event data.
To help illustrate this point, the figure below maps several groups of variables by their total variance (x-axis; logged) and the fraction of that variance that occurs between countries (y-axis; the data are monthly from 2001 to 2013). GDP, the Polity IV regime indicators, the EGIP count of excluded groups and other structural variables are clustered in the top quarter, meaning that whatever variance they display is mostly between countries, rather than within. This is where the predictions from structural models that use them as input have to fall as well (Sources: World Development Indicators, Polity IV, Ethnic Power Relations).
There are meaningful differences within this set of structural variables. Population and GDP have much higher variance (keeping in mind the x-axis is logged) than the remaining usual suspects like Polity IV autocracy and democracy scores, a count of excluded ethnic groups, and military expenditure. Notably, there are also some outliers like CPI and cell subscribers per 1,000 (both from the World Bank) that have surprising within-country variance, but which usually are not considered in models of conflict. But overall the structural variables are mainly useful for distinguishing countries, not timing.
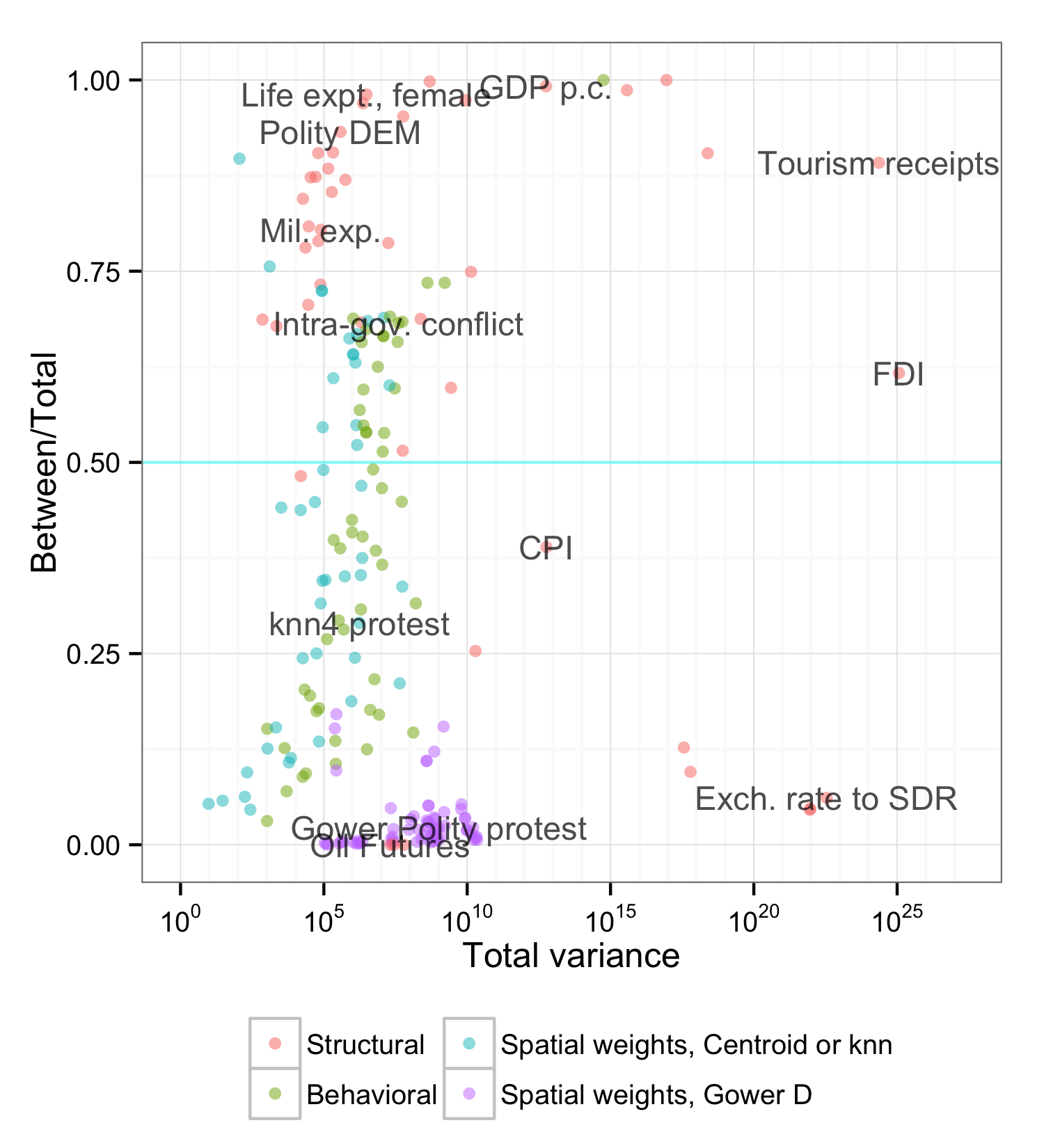
The second and third groups of variables in the plot are counts generated from the ICEWS event data and a couple of their spatial lags. Included are reports of protests against government (Anti-G Protests), intra-government conflict (verbal and material), and government violence against dissident groups (Gov. to Dis. mat. conflict). These event variables tend to fall in the mid-range, with decent variance that is roughly balanced between and within countries. The spatial lags are all of anti-government protests and differ in how neighborhoods and distance were defined, e.g. as protests in the nearest four neighbors, or based on Gower distance of political regimes. The spatial lags roughly keep the overall variation of the event indicators, but almost all of it now occurs within countries over time rather than within countries. Considering that spatial lags in essence smooth data over space, i.e. countries, this is to be expected. Both sets of variables, event counts and their spatial lags, have reasonable total variation that mostly occurs within countries over time, making them better candidates for pinning down the timing of events in countries that are likely to experience them.
One final variable related to the ICEWS event data has the highest total variance of all the variables we considered here: a count of the total number of ICEWS events for each country. By definition it is entirely between country variance. The fact that it varies more than population and GDP maybe hints at the media bias problems with such event data, but that’s for another post.
The takeaway point is that if we want to get the timing of events right, we need to look beyond conventional structural indicators and towards event-data based variables and how to properly use them in the context of prediction. And even among the structural variables recorded at the annual level we maybe need to consider some unconventional choices, like CPI or cellphones per 1,000, if we want to develop models that can accurately predict at the sub-annual level. By extension, the same logic holds for prediction with spatially-disaggregated data. Although here there is a plethora of geographic data already out there like land cover, road network, and topographic data, these tend to be temporally invariant and we will likely also have to draw on event data to get the timing right.
The plot above was created by decomposing the variance of a variable into two components, that between countries, and that within countries over time:
$$ Var_{total} = Var_{between} + Var_{within} $$
Which we can calculate using the values of a variable, xc,t for country c at time t, the country means, xc, and the overall mean of the variable, x:
With this, it’s easy to calculate the portion of variance that is between countries, which is the last piece needed to recreate the plot. The R code and data to create the two plots in this post, including a function for variance decomposition, are on github.